It’s now almost 30 days since the last blog post and we made some really good progress. If you haven’t kept up with us, then here’s a quick summary:
Content Moderation
One of the core principles of ImageMonkey is: Keep it open and accessible for everybody - without the need to sign up. While this is great from the user experience point of view, it brings some serious problems with it:
How can we make sure the uploaded content doesn’t contain any sensitive material?
Manual content moderation is possible, but doesn’t scale. That’s why we are investing some time and energy into mechanisms which (hopefully) can assist us with content moderation. One of those mechanisms is a NSFW detection engine, which pre-classifies each uploaded image with a NSFW score. This for sure can’t replace manual content moderation entirely, but definitely could help us to identify problematic images early in the process.
We started our experiment with a handful more or less randomly selected P**rnhub and Youtube videos, which were split up in frames and fed to a neural net. With now 10k frames in each category (NSFW/SFW) we already get some pretty decent results. Of course it is still far away from being perfect and produces some false positives, but as an initial attempt I am pretty satisfied with the result. The whole thing is still in an alpha phase and was only trained on nudity, but if you want to give it a try: It’s available here.
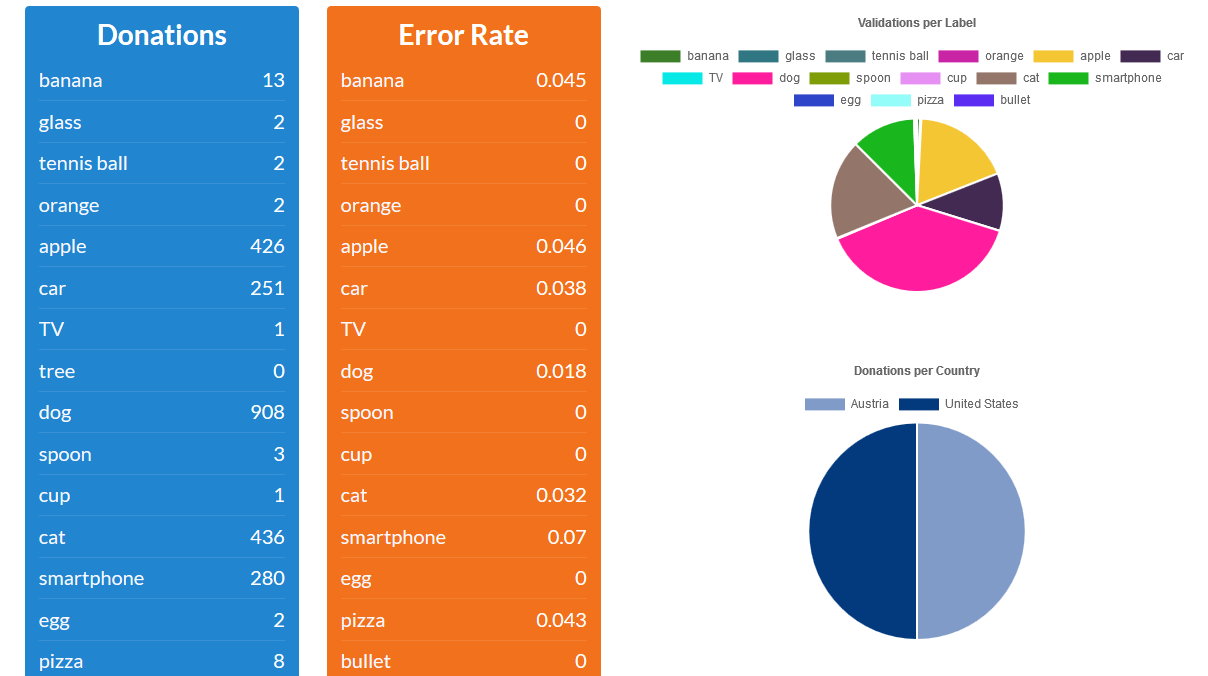
Dataset Statistics
The dataset statistics tab was completely reworked and now provides more detailed statistical insight into the dataset.
Important Info At ImageMonkey we are taking your privacy seriously, that means we do not store any personal information (like your IP address) in our database. Neither do we send your IP address to some external service to determine your geolocation. Instead, ImageMonkey uses a local geolocation database for the geolocation lookup.
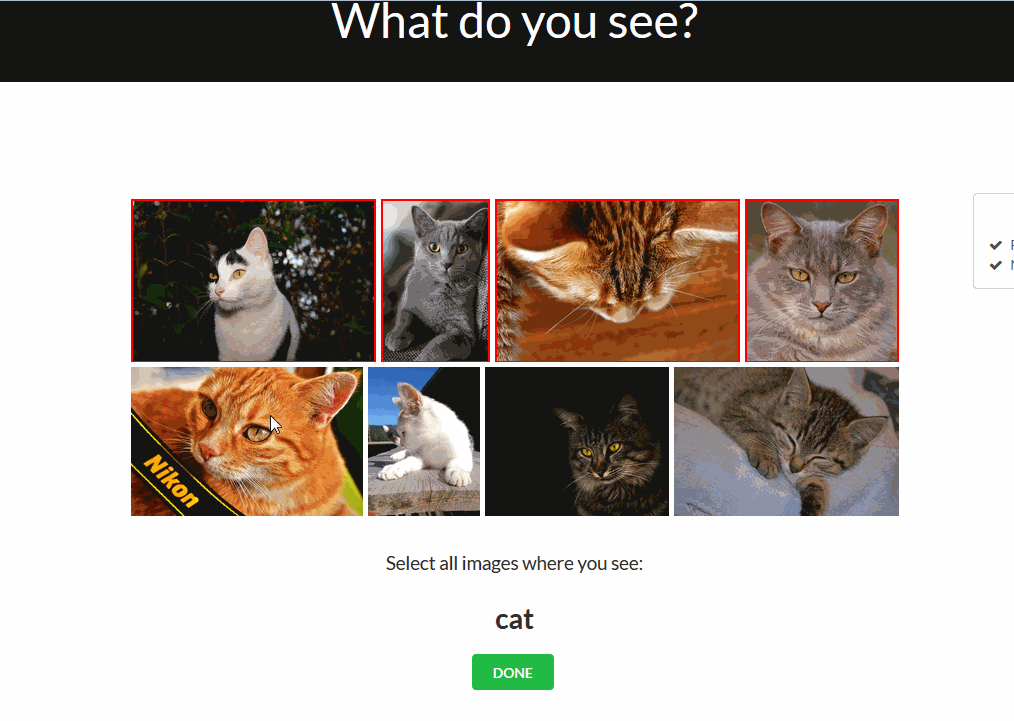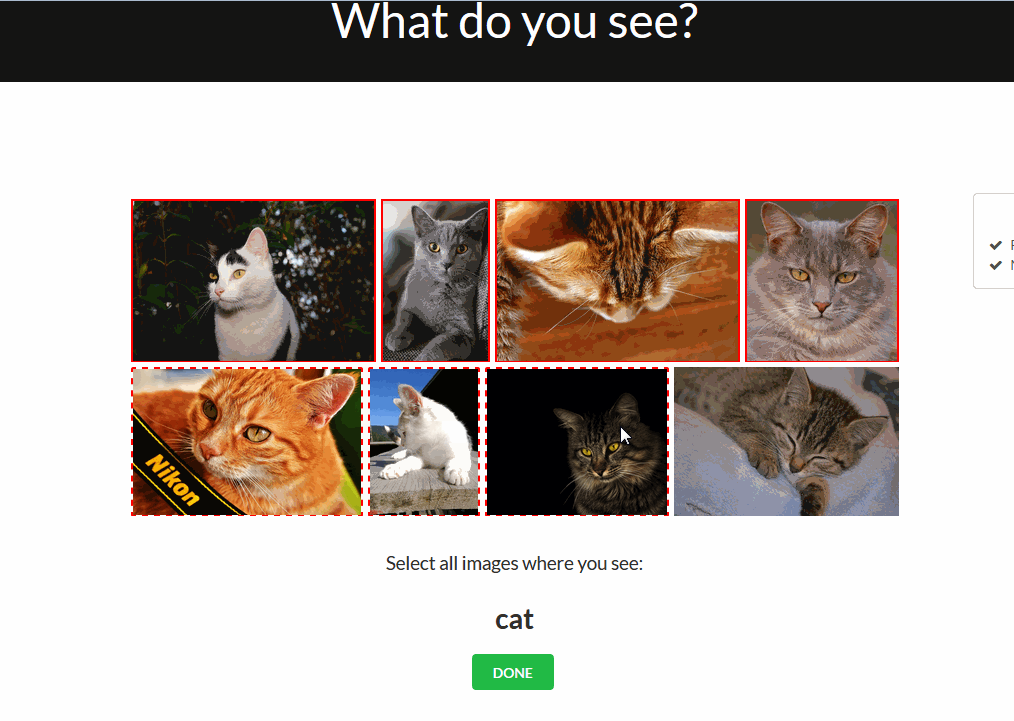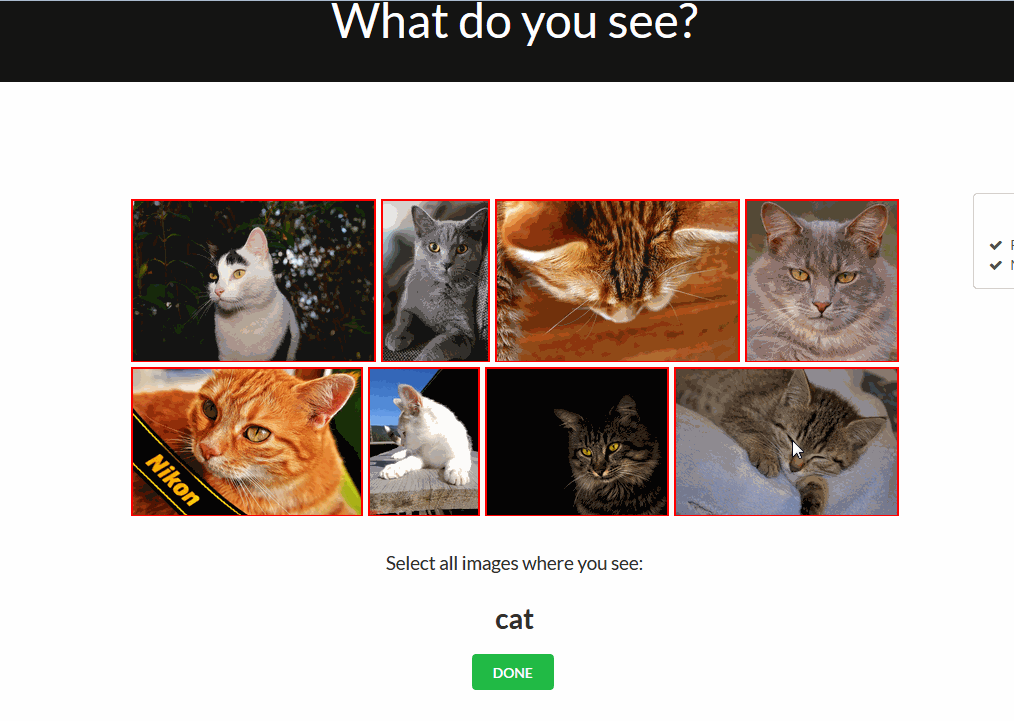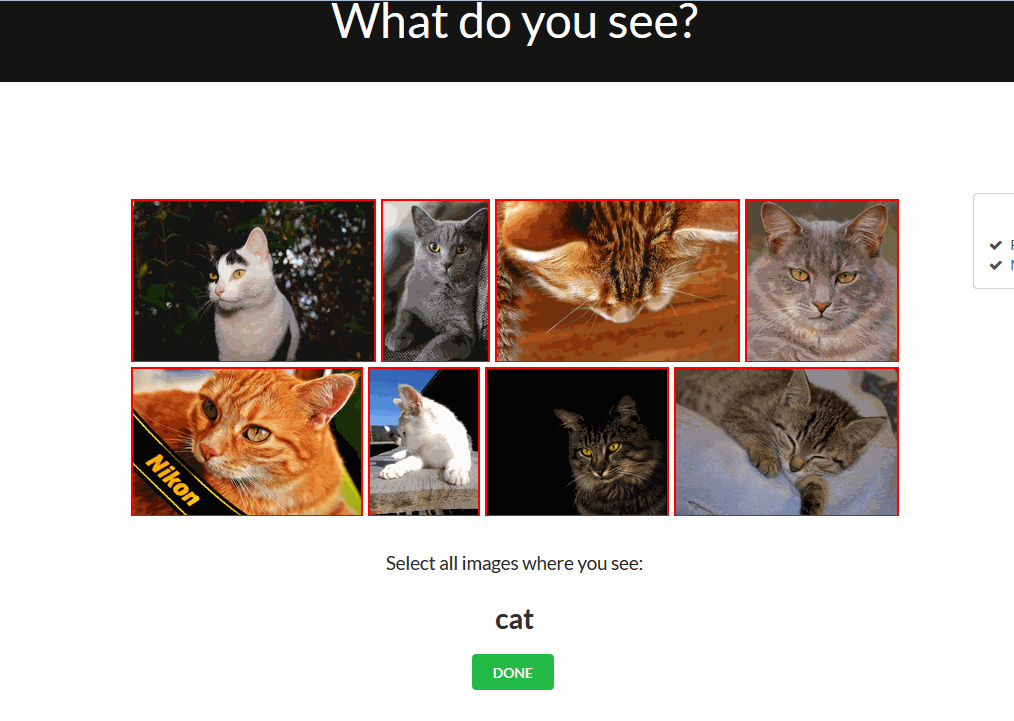
Multi Validation Mode
Another feature that’s still in beta mode, but already available for try out, is the Multivalidation Mode. The Multivalidation Mode is inspired by that reddit comment and allows users to validate multiple images in one go. You can enable it in the validation tab by clicking ‘m’ on your keyboard.
Detecting malicious behavior
While a completely open and publicly modifiable dataset has it’s benefits, it also gives users the possibility to destroy the dataset’s quality by maliciously voting for the wrong label on purpose.We for sure can’t prevent that, but we can try to make it harder. For that reason a history table was introduced, which now keeps track of every single action that’s performed on the dataset and in which way it affected the dataset.
Together with a browser fingerprint we get some pretty good information about the image’s state and how it changes over time (e.q if an image transitions from being classified as an ‘apple’ to being ‘not an apple’ in a very short time, it could be an malicious attempt).
Important info We do not store any personal information (like your IP address or your browser version) of you. The only thing we are storing is an anonymized hash.
Possibility to choose a label on upload
Up to now it wasn’t possible to select a label other than the one that was randomly chosen by the system. As this was quite inflexible and resulted in users pressing the refresh button of their browsers until the desired label would eventually show up, we decided to change that behavior.

Experiments
There are also some ongoing experiments and proof of concepts, which haven’t made it into an ImageMonkey release yet.
- Pre-annotation of video frames (based on background subtraction):

- Using the grabcut algorithm to select objects

- Gamification

- Validate an image each time you open a new browser tab
Want to contribute?
Once again, I would like to thank @dobkeratops for all the awesome ideas, the feedback and technical advice. Many thanks for your contribution!
As ImageMonkey and all it’s parts are completely OpenSource, every contribution is highly appreciated. In case you want to check it out, here are some links:
https://github.com/bbernhard/imagemonkey-core
https://github.com/bbernhard/imagemonkey-client
https://github.com/bbernhard/imagemonkey-playground
https://github.com/bbernhard/imagemonkey-chrome-extension
https://github.com/bbernhard/imagemonkey-admin