ImageMonkey is a public open source image dataset with powerful APIs and a tight integration of existing machine learning frameworks.
As of last week it seems that we’ve finally cracked the 100k milestone - the ImageMonkey dataset now contains over 100k CC0 licensed images, ~140k labeled objects, ~25k validations and over 100k annotated objects.
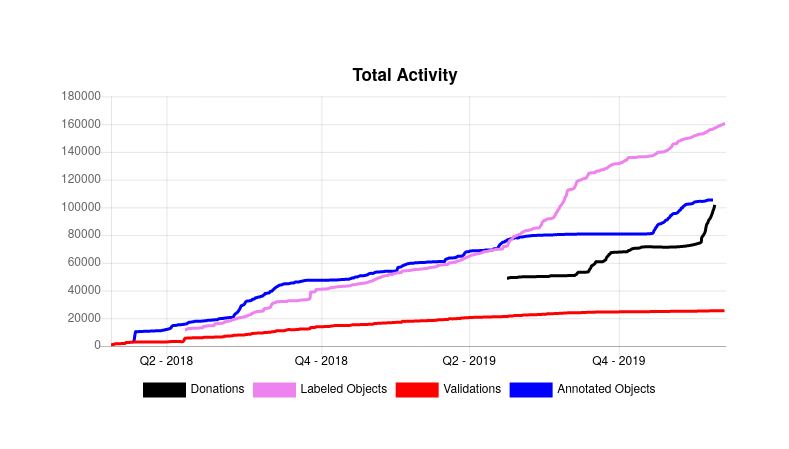
It’s now almost three years ago since I started working on ImageMonkey - at that time mainly to scratch my own itch. Back then, I was working on another project, which I thought had the potential to blow up (actually it flopped totally, but that’s a different story) and for that project I was looking for labeled gym equipment datasets to train a neural net on it. As it turned out annotated images are really hard to find - and it gets even harder if you are looking for a public domain dataset.
That’s when I thought to myself: Wouldn’t it be great if there exists such a public dataset? A dataset that’s not owned by a big company where you have to fear that at some point they will shut down the service and everything is lost (yeah, looking at you Yahoo). A dataset created by people for people. A dataset where eyerbody can contribute to. Something that’s easy to use.
There are millions of people in the world running around with their smartphones, snapping pictures of their dogs, cats and what they have for lunch. Wouldn’t that be great image material for a public domain dataset?
When creating ImageMonkey one of the primary goals was always simplicity and ease of use. ImageMonkey wasn’t primarily designed to be used by the “hardcore data labeler” (that’s not to say that that we do not provide tools for those as well), it was rather designed to be used the ordinary man and and woman. In order to accomplish that, the whole process of collecting data was split up in different tasks (“task based approach”).
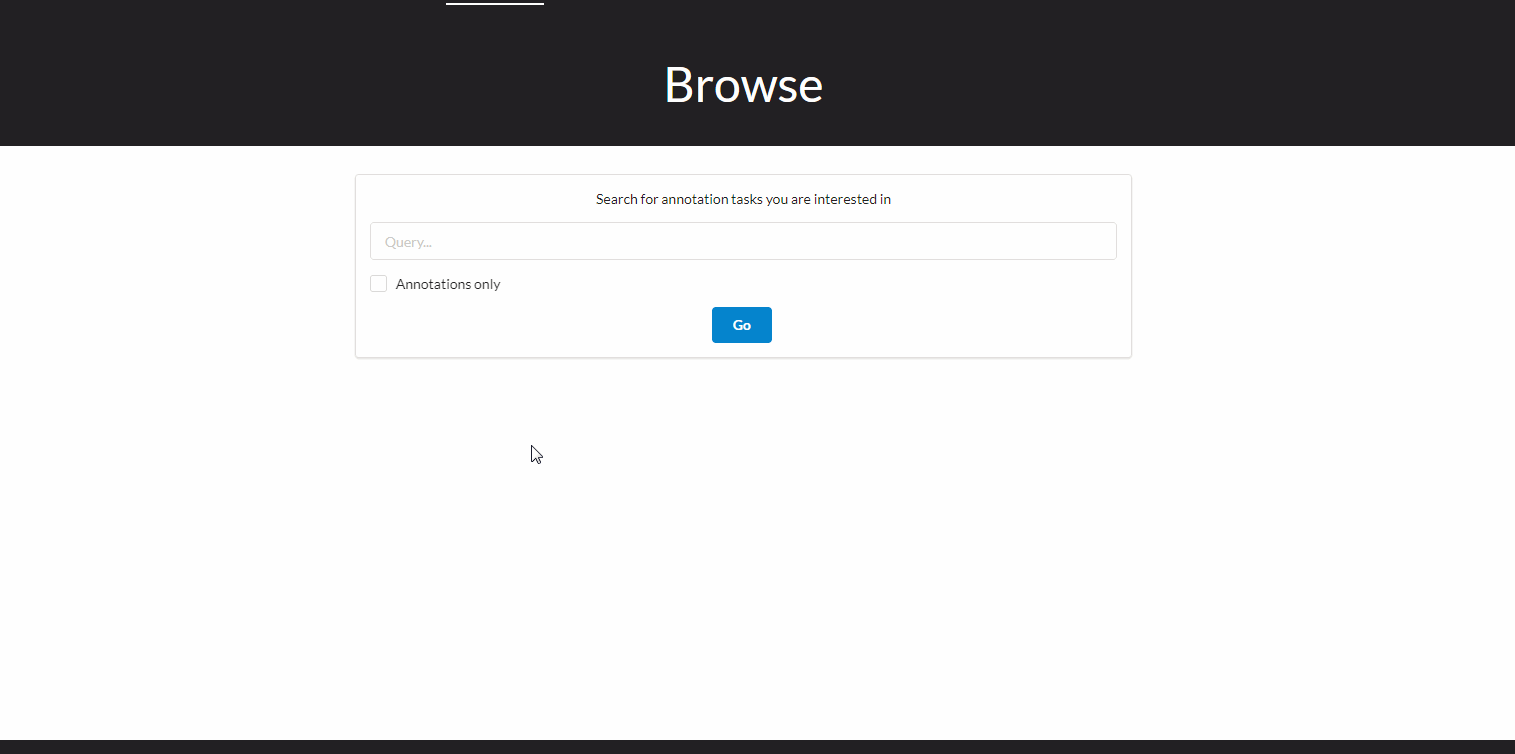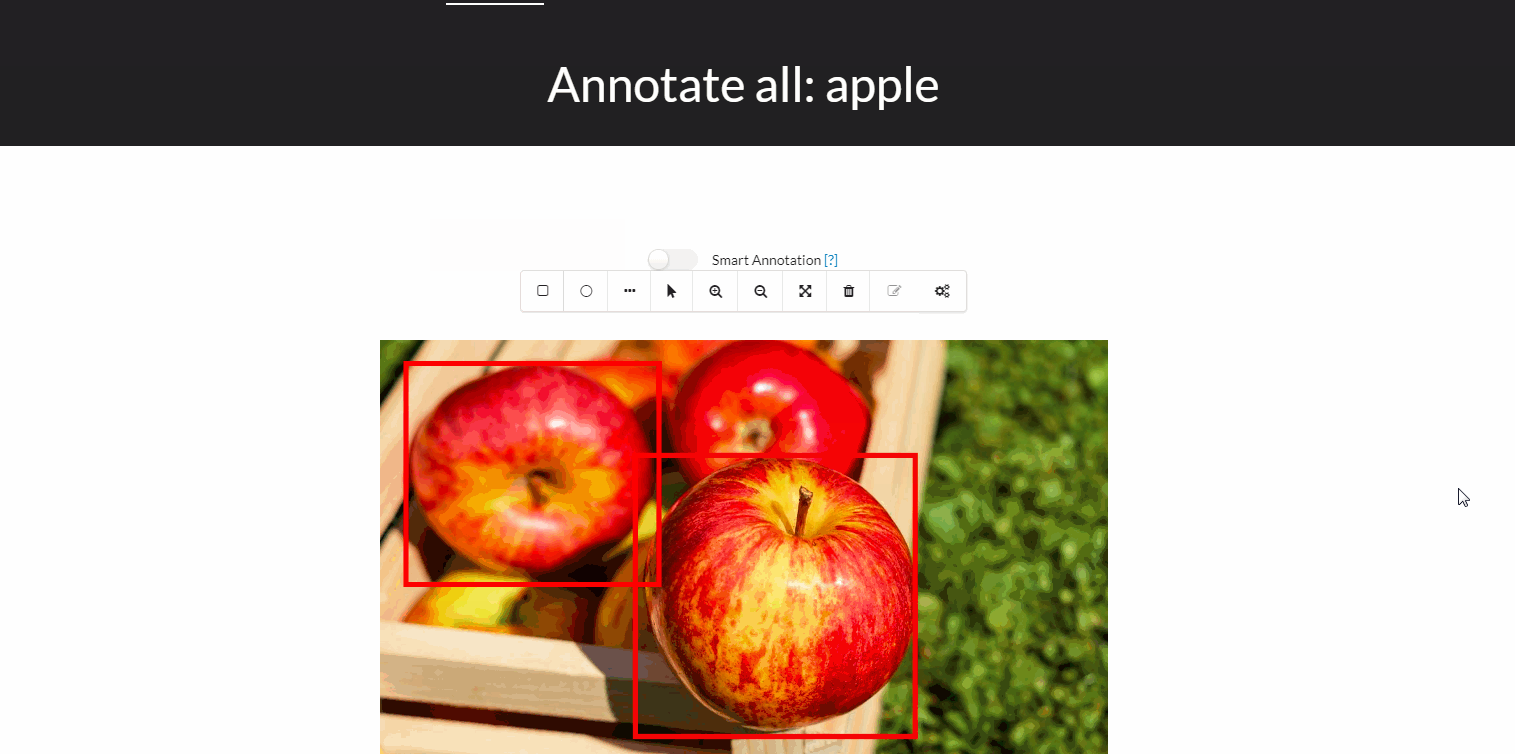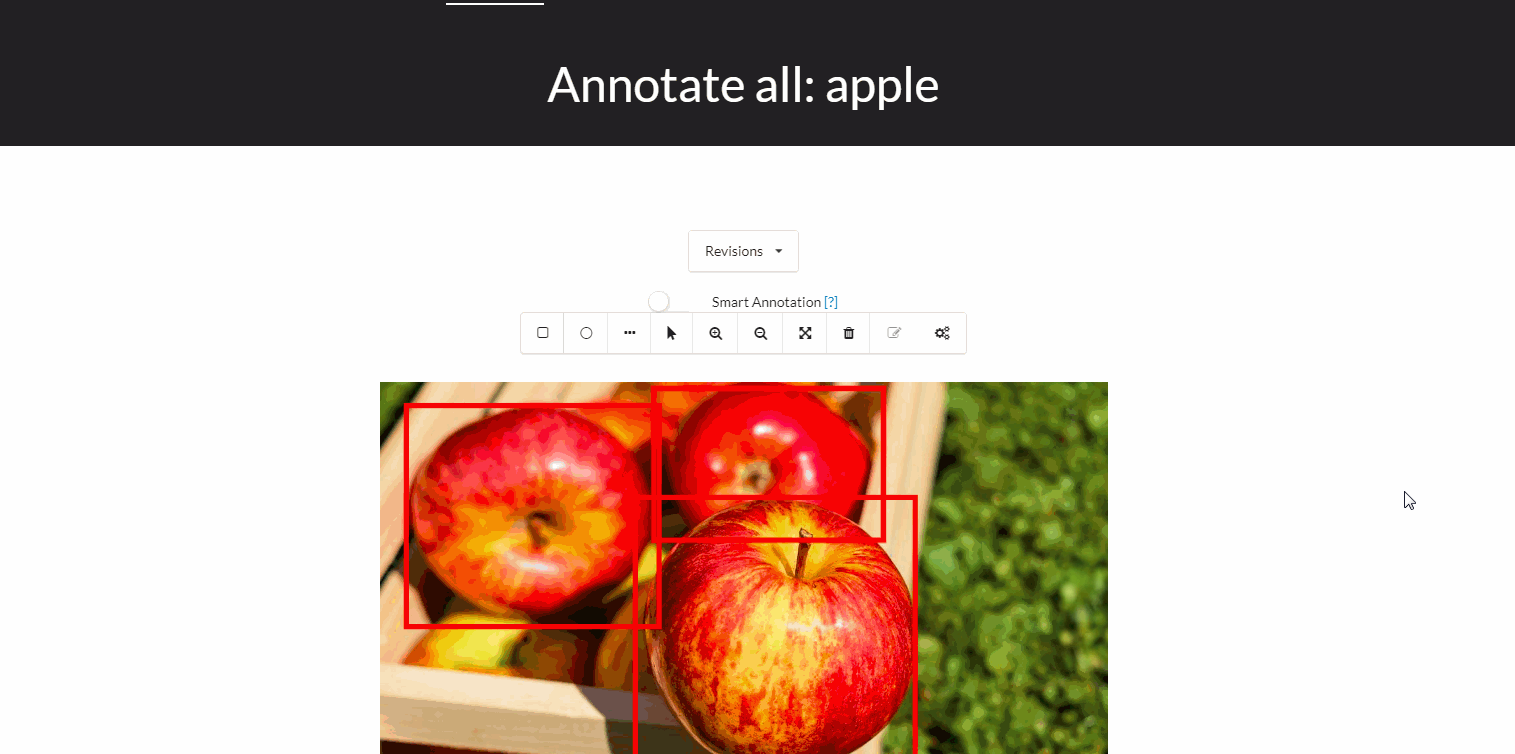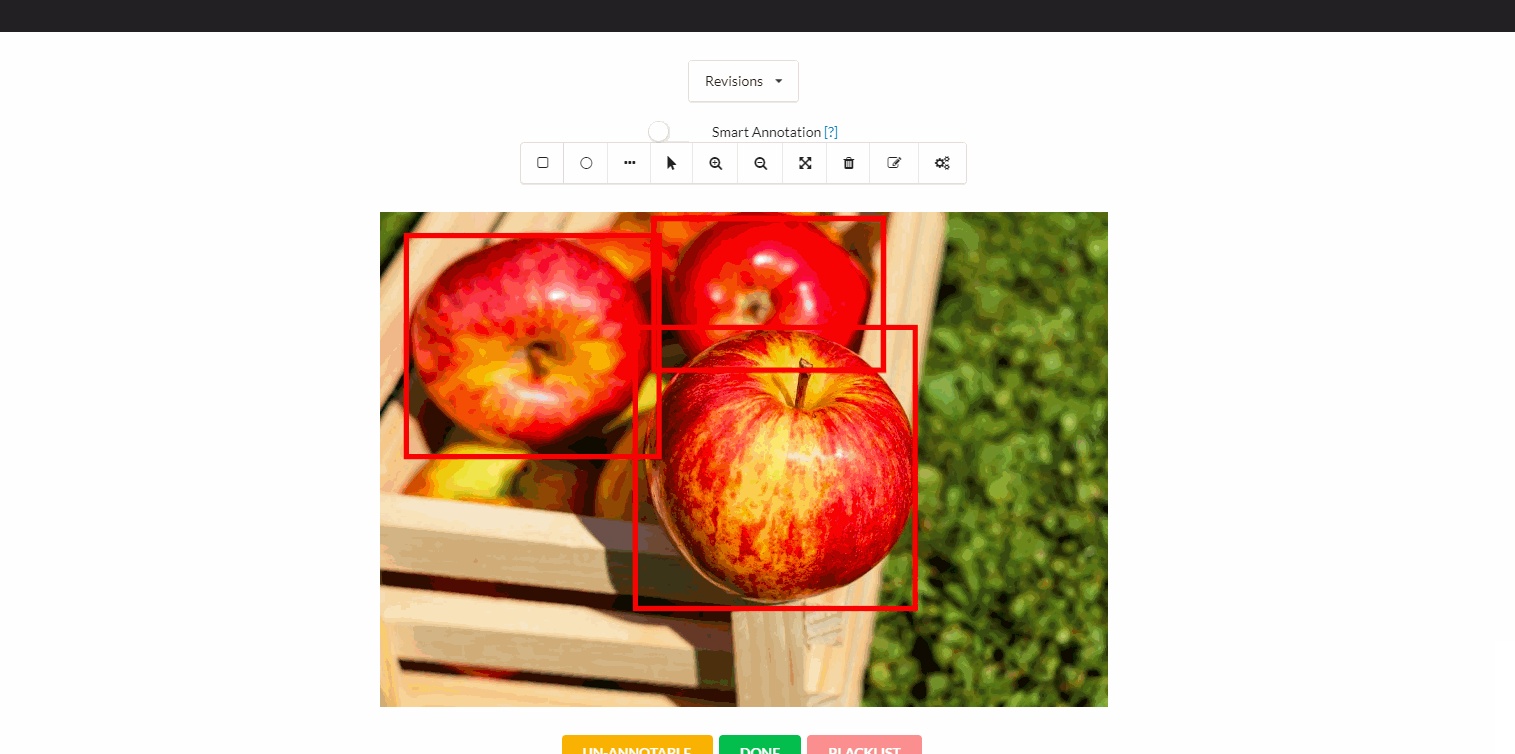
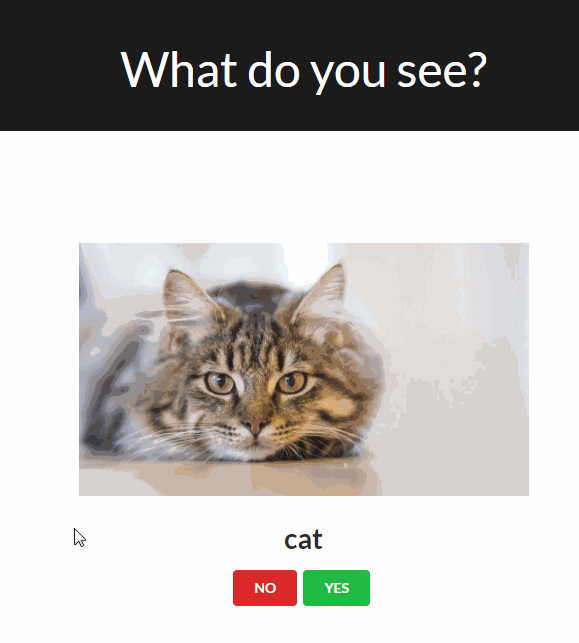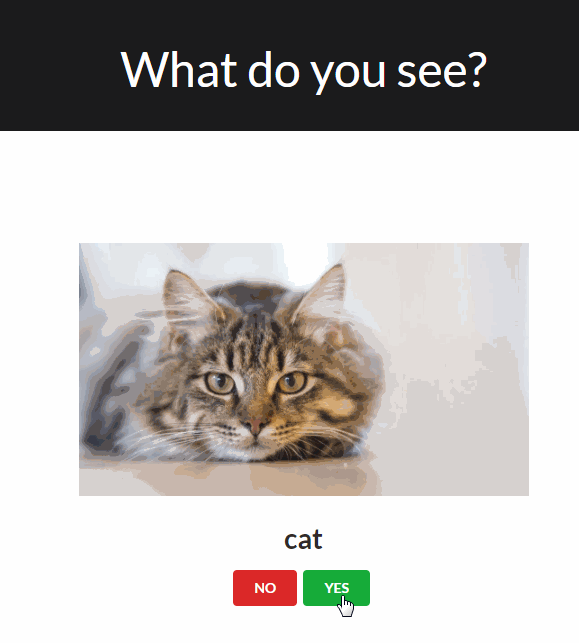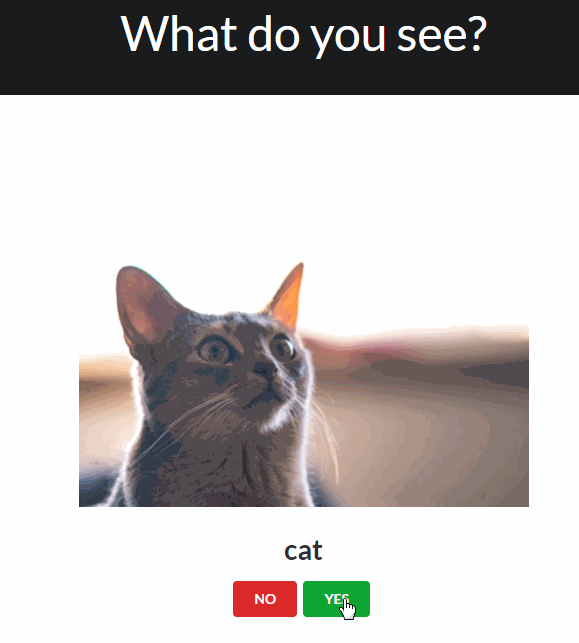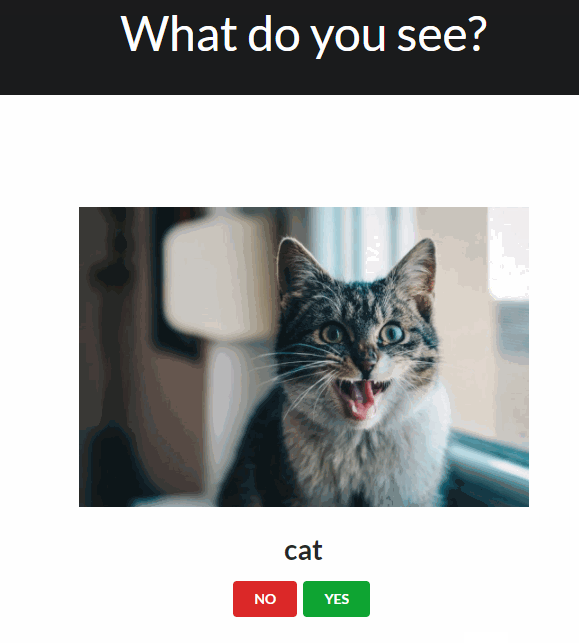
The traditional worflow of annotating an object usually looks like this:
- collect an image
- draw a bounding box around the object of interest
- label it appropriately.
With ImageMonkey it’s different. Every of those tasks can be done individually. You love taking pictures, but don’t want to tag them with labels? No problem, just upload the pictures without labels - that’s perfectly fine. You enjoy labeling images (I’ve heard that some people find that quite relaxing) but don’t want to draw bounding boxes around the objects? That’s fine, just do the labeling. As you can see, the complex task of annotating objects is broken down in much simpler tasks. The cool thing about that is, that it’s now possible to build APIs around those functionalities and use those APIs to create other applications.
In the Last Lecture (if you haven’t seen it, I highly encourage you to do so), Randy Pausch talks about head fake - a situation in which someone believes they are learning one thing, but are really learning something different. I am a huge fan of this concept and personally I think it not only works for learning something, but also for doing something.
While working on ImageMonkey I tried to make use of head fakes and incorporate them into the software I was building. Then, let’s be honest here: Collecting data for a dataset can be tedious and boring - so why not make it more fun?
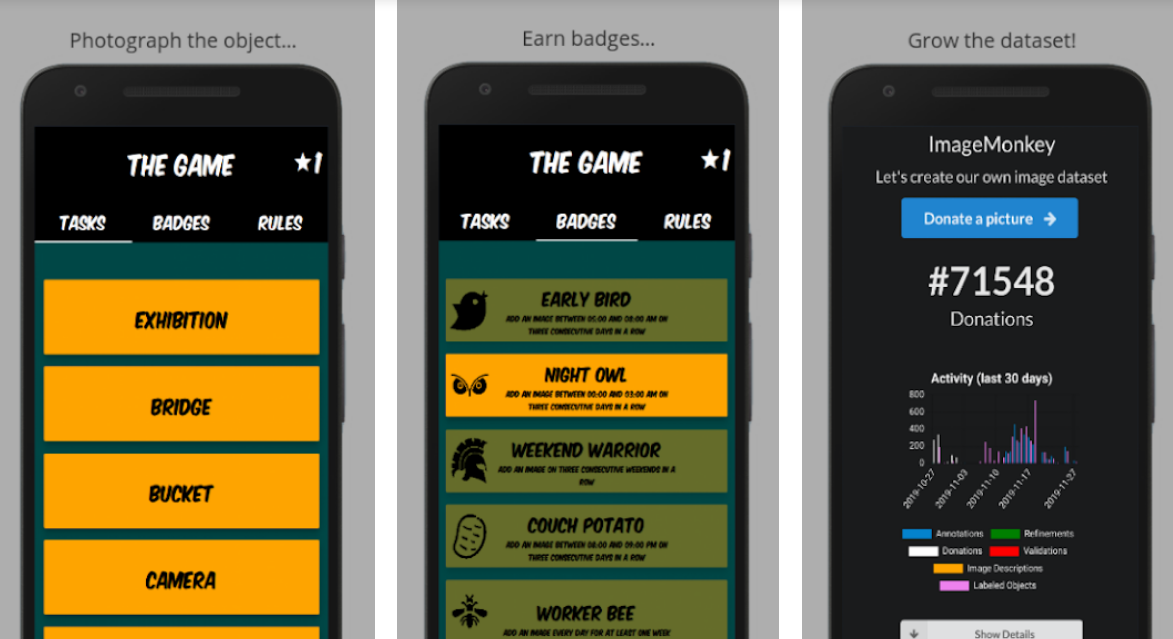
With the ImageMonkey Browser Extension and ImageMonkey - The Game I tried exactly that.
The ImageMonkey Browser Extension shows a random validation each time you open a new browser tab.
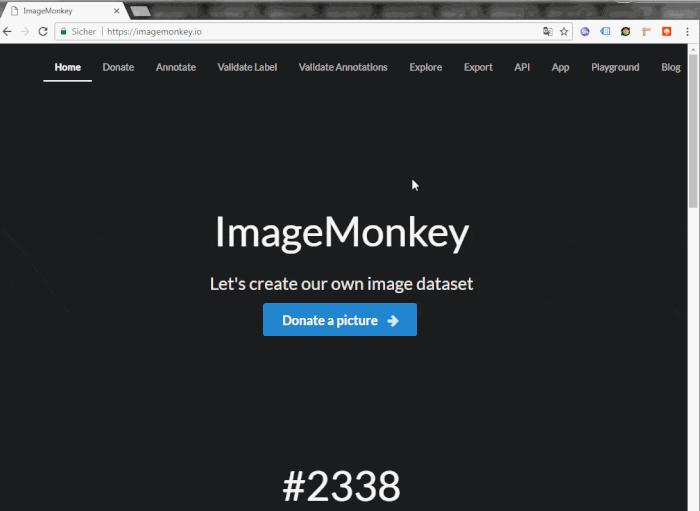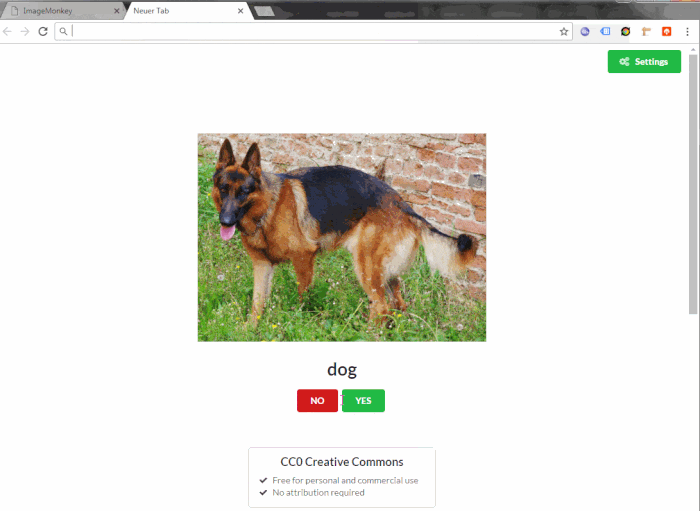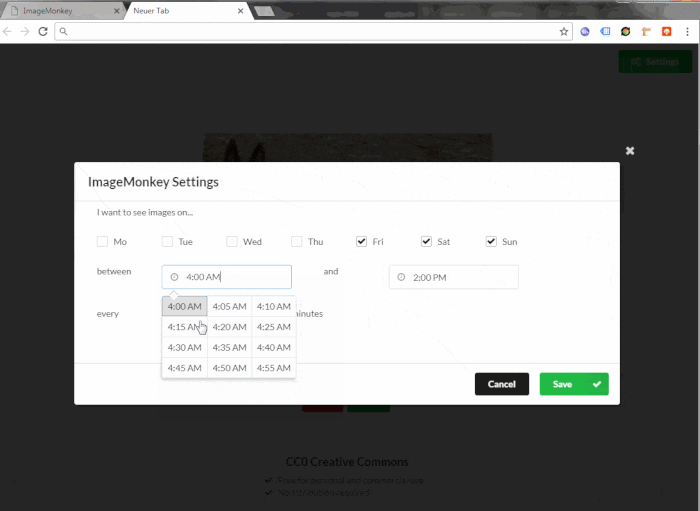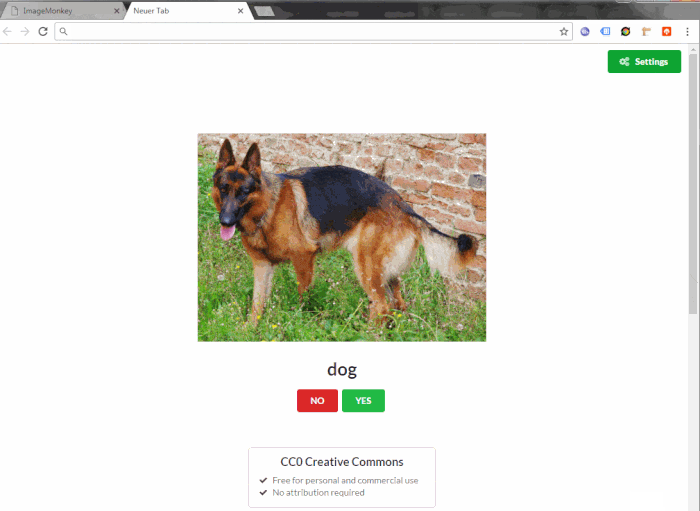
ImageMonkey - The Game uses gamification concepts to make image collecting more fun.
Powerful API and tight integrations of existing ML frameworks
ImageMonkey’s task based approach made it possible to build a REST API around all its functionality, which not only allows developers to easily export data, but also gives them the possibility to feed back data their own.
Due to the tight integration of existing machine learning frameworks like Tensorflow and Mask RCNN it’s possible to train a neural net for image classification, object detection and object segmentation with just a handful of commands.
e.g If you want to train a cat/dog image classifier via transfer learning on a pre-trained inception-v3 model, all you need to do is:
docker pull bbernhard/imagemonkey-train:latest-gpu
docker run --runtime=nvidia -it bbernhard/imagemonkey-train:latest-gpu
monkey train --labels="cat|dog" --type="image-classification"
The monkey script automatically downloads the necessary data from ImageMonkey, configures the tensorflow pipeline and then starts tensorflow for training. When the training is done, the script spits out a ready-to-go graph.pb file.
What exactly is a public open source image dataset?
Every line of code that was ever written for the ImageMonkey project is available on Github - i.e if you want to spin up your own (private) ImageMonkey instance for collecting data you can easily do that. But it’s not only that. Every item in the ImageMonkey dataset is licensed under the CC0 license. Which basically means you can do the f*ck you want with it - no strings attached. Furthermore, the whole dataset (i.e the images + an obfuscated database dump) gets uploaded to the internet archive on a regular basis (see here for details).
What’s next?
Hosting ImageMonkey (and all it’s services) costs money. At the moment everything’s running on two big Hetzner bare metal servers (one of them being a GPU instance). And while the server costs are still affordable for me, I would really like to see ImageMonkey getting self sustainable.
Apart from that, I’ll be working on:
- a better annotation editor
- improve the ML pipeline to provide models for download on a regular basis
- some general improvements
Thanks
Last but not least I want to thank @dobkeratops - ImageMonkey wouldn’t be where it is right now without your help. Thanks a lot for all your contributions!
Want to contribute?
Any help is really appreciated - whether it is help with the codebase, contributions to the dataset or financial support. Let’s create our public image dataset together!